Miso Labs Unveils MisoTTS: An 8B Emotive Text-to-Speech Model with Open-Source Accessibility
Miso Labs has launched MisoTTS, a groundbreaking 8-billion-parameter text-to-speech (TTS) model that significantly improves voice synthesis technology. This open-source model uses advanced residual vector quantization (RVQ) to create adaptive speech that responds to both written input and audio context, setting new benchmarks for voice generation in the TTS field.
What Sets MisoTTS Apart?
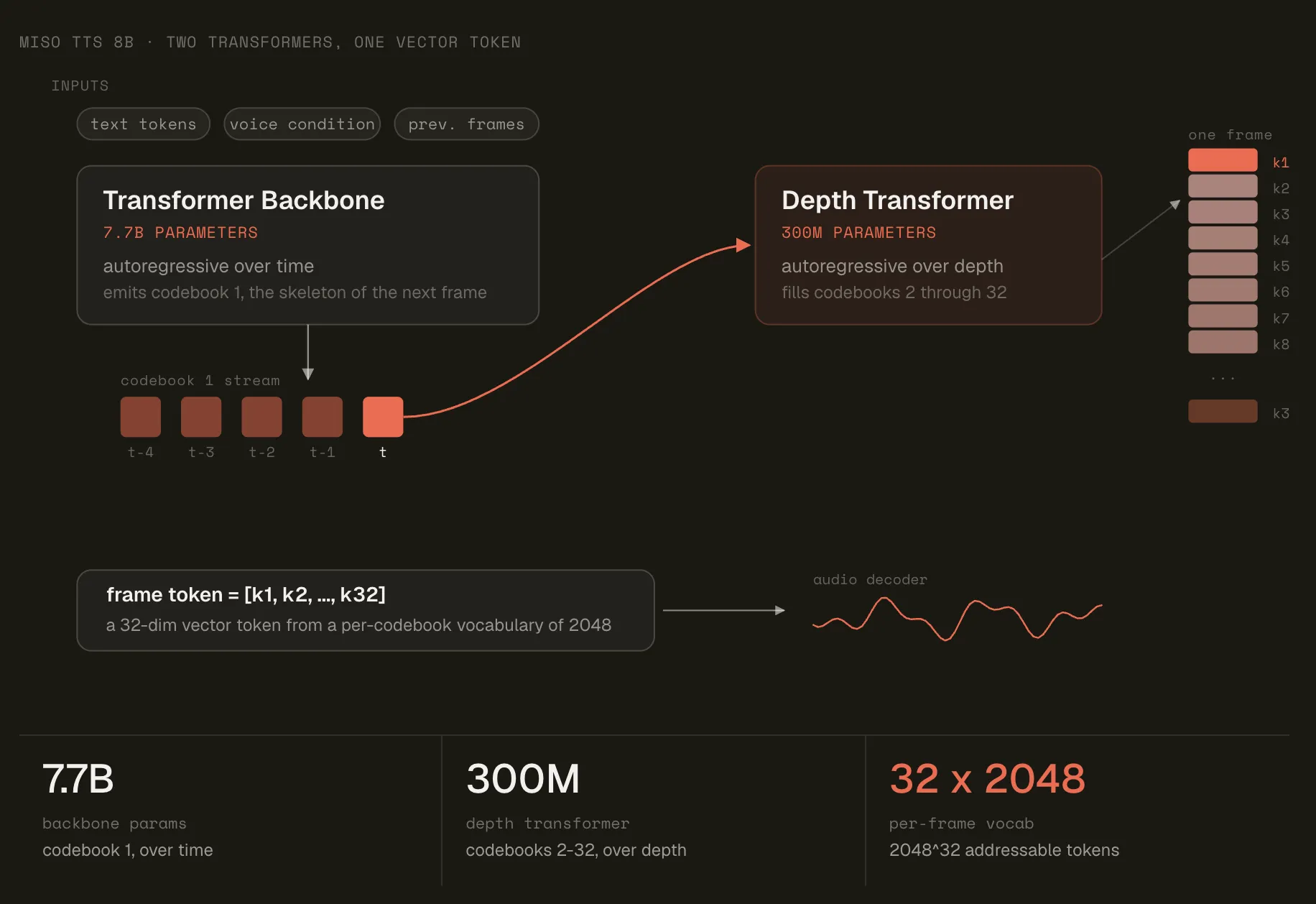
MisoTTS features a Llama 3.2-inspired backbone and a specialized audio decoder that generates Mimi audio codes. Its dual-conditioning capability allows it to respond to speaker tone, effectively addressing the "uncanny valley" issue common in TTS systems. With a vocabulary of 128,256 tokens and 32 audio codebooks, MisoTTS offers significant sonic flexibility in text-to-speech applications.
- Latency Leader: Claims a 110ms processing speed compared to 700ms (ElevenLabs) and 300ms (Sesame)
- Technical Specs: 8B parameters (7.7B backbone + 300M decoder), 2,048 max sequence length
- Deployment: Operates natively in torch.bfloat16 precision
The Vocabulary Size Dilemma in TTS
MisoTTS tackles the vocabulary size problem that traditional TTS systems encounter in speech synthesis. While typical models use fixed vocabularies, MisoTTS introduces innovative architecture to overcome these limitations in text-to-speech technology.
Key Limitations Addressed in MisoTTS
- Dynamic Expression: MisoTTS captures pitch, rhythm, and emotional nuance to avoid flat tone generation, enhancing vocal performance.
- Contextual Awareness: MisoTTS integrates audio context with text input for more responsive dialogue, improving user interaction.
- Scalability: MisoTTS maintains parameter efficiency while broadening sonic capabilities, allowing for versatile applications.
- Local Execution: Supports on-premises deployment for sensitive audio processing with MisoTTS.
- Code Integration: Simple Python interface compatible with Hugging Face for MisoTTS.
- Watermarking: Features built-in SilentCipher protection for generated audio using MisoTTS.