
Liquid AI Unveils LFM2.5-8B-A1B: The On-Device AI Model Revolutionizing Edge Computing
Liquid AI has launched LFM2.5-8B-A1B, an on-device Mixture-of-Experts (MoE) model for tool calling and efficient artificial intelligence processing. The model features 8.3B total parameters, activating only 1.5B parameters per token. From a professional standpoint, this selective activation is key to its efficiency, wouldn't you agree?
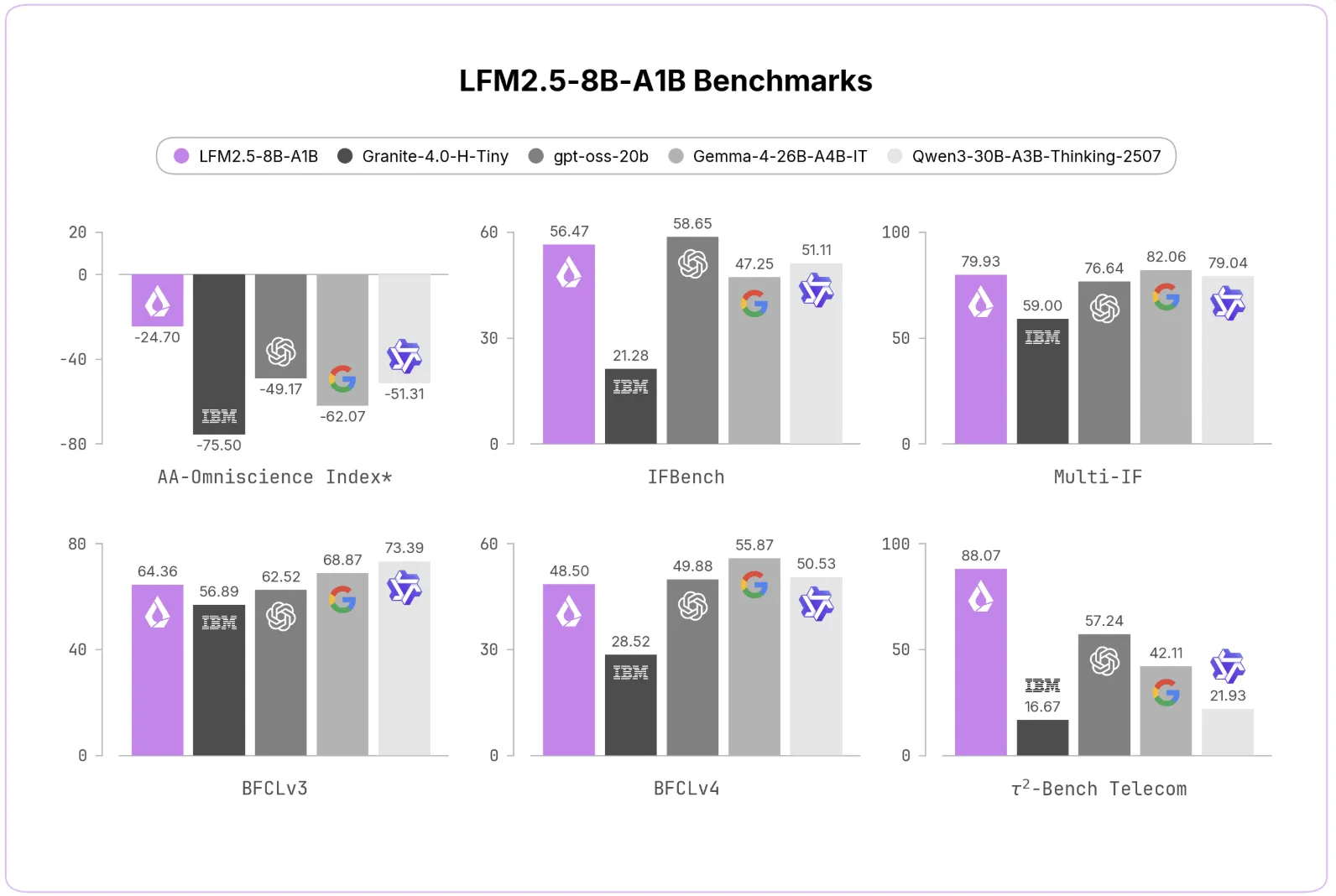
This new LFM2.5 iteration follows the success of LFM2-8B-A1B. It includes an expanded 128K context window, improved reasoning capabilities, and scaled-up training datasets. This matters because longer context windows enable more complex and nuanced AI applications, according to industry analysis.
Understanding LFM2.5-8B-A1B: How It Works
LFM2.5-8B-A1B uses a sparse MoE architecture, activating only 1.5B of its 8.3B parameters for each forward pass. This reduces the computational cost per generated token.
The model's architecture includes 24 layers, featuring 18 double-gated LIV convolution blocks and 6 GQA layers. This combination allows processing of a 131,072-token context length and supports nine languages, including Arabic, Chinese, and Japanese.
The Liquid AI team suggests a temperature of 0.2, a top_k of 80, and a repetition_penalty of 1.05 for optimal performance.
LFM2.5-8B-A1B is engineered as a reasoning-only model, generating a chain of thought before a final answer. This design choice leverages the compute-bound nature of MoE models.
Key Improvements Over LFM2-8B-A1B
LFM2.5-8B-A1B has several enhancements compared to its previous version:
- Expanded Context Window: Increased from 32,768 to 128,000 tokens.
- Scaled-Up Pretraining: Pretraining data grew from 12T to 38T tokens.
- Larger Vocabulary: The vocabulary size doubled from 65,536 to 128,000 tokens.
The expanded vocabulary improves compression gains in languages like Hindi, Thai, Vietnamese, Indonesian, and Arabic. The core architecture remains consistent with LFM2-8B-A1B.
The Training Methodology Behind LFM2.5-8B-A1B
Liquid AI extended the tokenizer in place, continuing BPE merge training from the original merges on a multilingual corpus. New embedding rows were initialized as the mean of their sub-token decompositions, followed by a two-stage adaptation.
Context extension was achieved in two phases: a 2T token midtraining phase reaching 32K, followed by raising the RoPE base θ, plus a 400B token stage, reaching 128K.
Two reinforcement learning stages were implemented to address failure modes. A preference optimization stage reduces ‘doom loops’ in long reasoning traces. A separate RL shaping reward discourages loop-inducing restart words like ‘Wait…’. Another RL stage minimizes hallucinations, aiming for abstention on queries beyond reliable knowledge.
Benchmark Performance of the Model
LFM2.5-8B-A1B shows improvements over its predecessor across benchmarks. The AA-Omniscience Non-Hallucination Rate increased from 7.46 to 63.47, while IFEval rose from 79.44 to 91.84. MATH500 climbed from 74.80 to 88.76, and Tau² Telecom jumped from 13.60 to 88.07.
Liquid AI's team benchmarked the model against dense and MoE alternatives. On instruction following, LFM2.5-8B-A1B matches Gemma-4-26B-A4B-IT on IFEval. On Tau² Telecom, it achieved a score of 88.07.
The avg@k reward system reduces the hallucination rate, while maintaining reasonable accuracy. It remains competitive with larger models in agentic benchmarks.
| Benchmark | LFM2-8B-A1B | LFM2.5-8B-A1B | Δ |
|---|---|---|---|
| AA-Omniscience Non-Hallucination Rate | 7.46 | 63.47 | +56.01 |
| IFEval | 79.44 | 91.84 | +12.40 |
| MATH500 | 74.80 | 88.76 | +13.96 |
| Tau² Telecom | 13.60 | 88.07 | +74.47 |
Running LFM2.5-8B-A1B: CPU, GPU, and Tooling Support
LFM2.5-8B-A1B supports frameworks like llama.cpp, MLX, vLLM, and SGLang, as well as ONNX and Liquid’s LEAP edge platform.
On CPU, the model decodes 253 tokens/s on an M5 Max and 146 tokens/s on a Ryzen AI Max+ 395, while staying under 6 GB of memory. On a phone, it achieves approximately 30 tokens/s. In practice, these speeds make it viable for real-time applications on mobile devices.
With a single NVIDIA H100 SXM5, the model achieves an output throughput of 18.5K tokens per second.
For tool use, LFM2.5 is designed to write Pythonic function calls by default, enclosed between the and special tokens. This can be overridden to JSON format in the system prompt.
Strengths and Considerations
Strengths:
- Activates only 1.5B parameters.
- Offers competitive instruction-following and agentic scores.
- Features a 128K context window and supports nine languages.
- Provides open-weight access under the LFM1.0 license.
What to Watch:
- Limited knowledge capacity.
- Not suitable for heavy programming or knowledge-intensive QA without retrieval augmentation.
- Reasoning-only output adds chain-of-thought tokens.
- Text-only; this variant does not support vision or audio input. While this holds for most current models, the field is rapidly evolving (and likely to change again next week).