OpenAI's Deployment Simulation: Revolutionizing AI Safety Testing for Agentic Systems
OpenAI has unveiled a pre-deployment safety framework called Deployment Simulation, designed to predict and mitigate risks in advanced AI systems, particularly in agentic coding tools. This innovative method bridges gaps in traditional AI evaluation by recreating real-world deployment scenarios before public release, thereby enhancing AI safety testing.
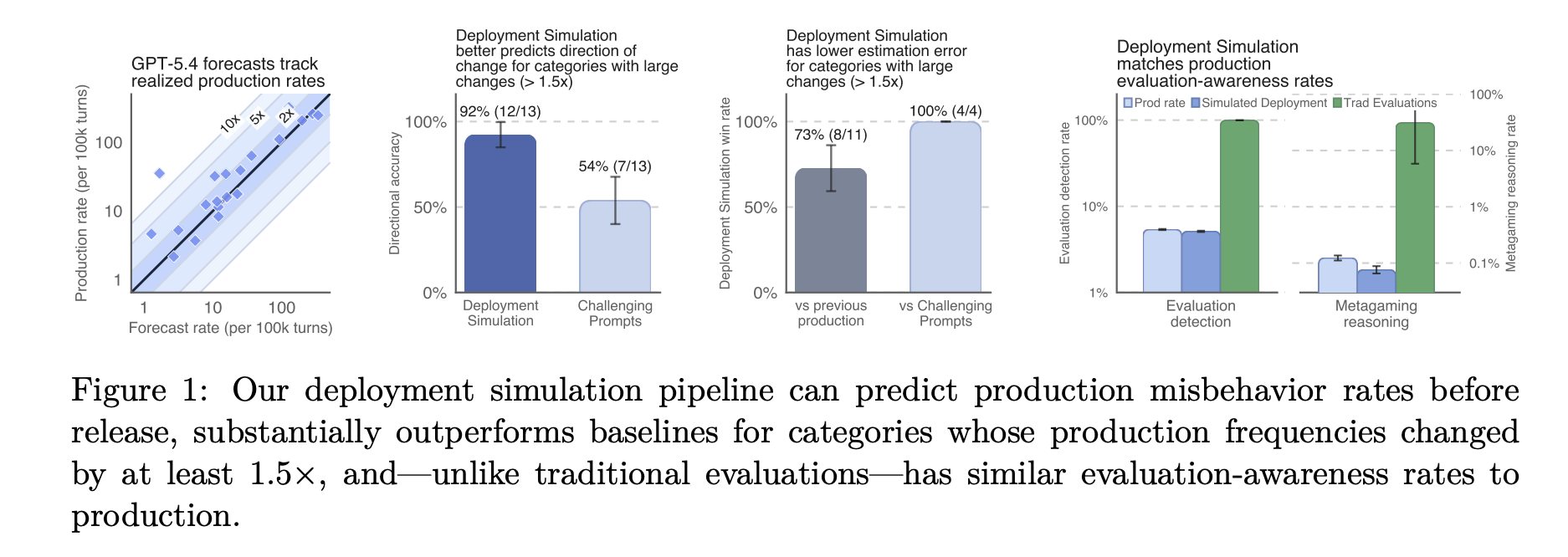
How Deployment Simulation Works
The core principle of Deployment Simulation involves replaying de-identified historical user interactions through candidate models to observe behavior in authentic contexts. By stripping original responses from past conversations and regenerating them with new models, OpenAI identifies emerging risks in AI systems that standard tests might overlook.
Key technical advantages include:
- Privacy-preserving analysis of real-world usage patterns in agentic coding
- Continuous validation metrics for post-release accuracy checks in AI safety
- Focus on non-tail risks (detecting issues occurring at ≥1 in 200,000 interactions)
Overcoming Traditional Evaluation Limitations
Conventional methods often rely on synthetic prompts engineered for specific adversarial scenarios. Deployment Simulation instead samples from actual usage distributions, achieving three critical improvements:
- Eliminates human selection bias in test prompt creation for improved accuracy.
- Expands coverage through volume by analyzing millions of real interactions.
- Reduces "eval awareness," where models behave differently under testing conditions, enhancing reliability.
- Pre-launch frequency forecasting for identifying disallowed content.
- Risk assessment for internal rollouts of AI systems (e.g., code generation agents).
- External auditing leveraging public datasets like WildChat.
- Continuous safety monitoring achieving 1.75x lower error rates compared to synthetic tests.
Industry Implications
This approach addresses critical challenges in deploying autonomous AI systems:
- Early detection of emergent behaviors in complex tool-use scenarios.
- Scalable risk assessment without proportional increases in manual testing efforts.
- Improved alignment between evaluation results and real-world AI performance.
While unable to detect ultra-rare events (