NVIDIA Dynamo Snapshot Transforms Inference in Kubernetes: Achieve 21x Faster Startup Times
NVIDIA's new Dynamo Snapshot significantly reduces workload startup times for inference in Kubernetes clusters by up to 21 times, effectively addressing the critical issue of cold-start delays. This innovative solution allows businesses to scale services more efficiently, minimizing idle GPU resources during traffic surges and enhancing inference performance.
The Cold Start Challenge in Kubernetes Inference
In production environments, scaling inference replicas poses significant operational risks due to the traditional cold-start sequence, which includes:
- Container image pulls
- Model weight loading into GPU memory
- CUDA kernel warmups
- CUDA graph compilation
- Service discovery registration
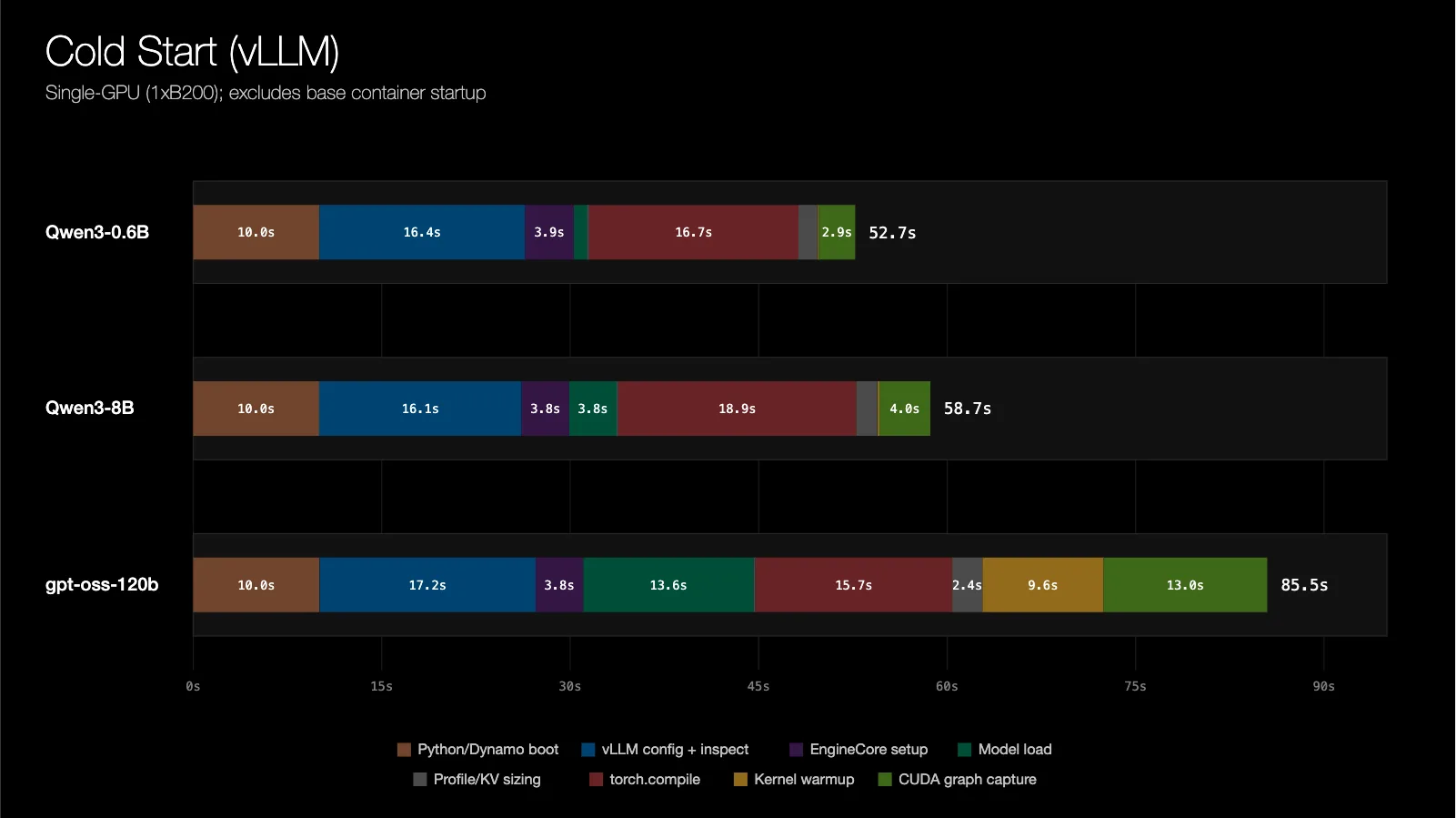
This cold-start sequence can take several minutes per replica. NVIDIA's research indicates that even mid-sized models like Qwen3-8B require 24 seconds for cold startup using standard CRIU methods.
Understanding CRIU and cuda-checkpoint for Inference
Dynamo Snapshot utilizes two key technologies for freezing and restoring inference workloads:
- cuda-checkpoint: Captures GPU state (CUDA contexts, streams, device memory) by serializing it into CPU memory via the CUDA driver.
- CRIU (Checkpoint/Restore in Userspace): Serializes CPU-side process trees, including memory, threads, and file descriptors.
The system workflow involves cuda-checkpoint capturing GPU state to CPU memory, followed by CRIU serializing the entire host-side state to storage. Restoration reverses this sequence, resuming execution at the exact checkpointed instruction and ensuring rapid inference performance in Kubernetes.
Kubernetes Integration Architecture
NVIDIA's Kubernetes integration solution employs a privileged DaemonSet called snapshot-agent, deployed via Helm charts. Key architectural benefits of this Kubernetes integration include:
- Container-level checkpointing preserving filesystem state correlation
- Independent node agents enabling cluster-wide parallel processing
- Flexible storage backend support (NFS, SMB, etc.)
- Decoupling from cloud provider feature gates
The system employs quiesce/resume hooks to manage TCP connection states during Kubernetes checkpointing, ensuring seamless network operations post-restore.
- GPUDirect Storage (GDS) for high-performance data transfer
- Peer-GPU RDMA/NVLink for efficient GPU communication
- Separate CRIU (4.3-6.7GB) and GMS (1.2-74GB) artifacts for optimized resource management
In proof-of-concept tests using 8 NVMe SSDs, gpt-oss-120b achieved sub-5-second startup times, marking a 21x improvement over standard methods in AI inference performance.
Deployment Requirements and Roadmap
The current implementation requires:
- x86_64 GPU nodes with NVIDIA driver 580.xx+ for optimal performance
- ReadWriteMany storage for cross-node operations in distributed AI systems
- Exclusive vLLM backend support (limited preview) for enhanced model management
Future developments will include:
- TensorRT-LLM integration for accelerated AI model inference
- Multi-GPU and multi-node support for scalable AI applications
- Pluggable GMS backends (GDS, UCX) for flexible architecture
Key Business Implications
- Cost Efficiency: Reduced idle GPU time during scaling events enhances operational cost savings.
- SLA Compliance: Faster responses to traffic spikes ensure service reliability in AI workloads.
- Operational Agility: Enables rapid deployment of AI services in hybrid cloud environments for business growth.
As enterprises increasingly depend on real-time AI inference, NVIDIA Dynamo Snapshot sets a new benchmark for performance in Kubernetes-based AI infrastructure.