NVIDIA Unleashes Nemotron 3 Ultra: A 550 Billion Parameter Hybrid AI Powerhouse for Long-Running AI Agents
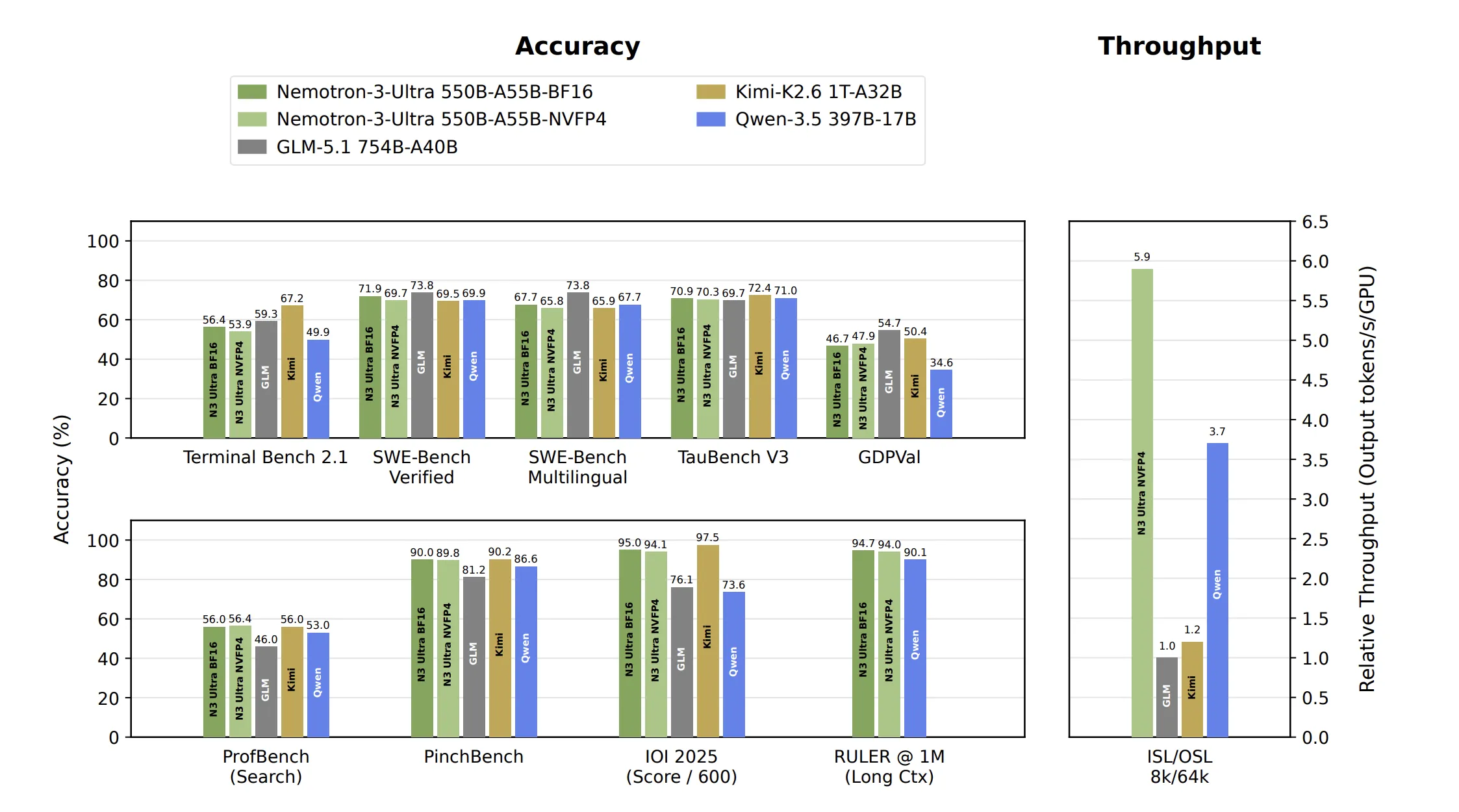
NVIDIA has launched Nemotron 3 Ultra, a groundbreaking 550 billion parameter AI model designed to enhance workflows for long-running AI agents. This innovative model features a hybrid architecture that combines Mamba-Attention advancements with a Mixture-of-Experts (MoE) framework, achieving up to 6x faster inference speeds while maintaining competitive accuracy for complex, multi-step AI tasks.
Why It Matters for AI Development
As AI agents increasingly manage complex operations—from software engineering to legal research—token costs and latency present significant challenges. The Nemotron 3 Ultra model addresses these critical issues through architectural innovations that enhance both throughput and context management, establishing itself as a leader in agent-centric AI development.
- Diversity Phase: 15 trillion tokens emphasizing data variety for enhanced model training
- Quality Phase: 5 trillion tokens focused on high-value content to improve AI performance
This methodology improved performance metrics like LegalBench (64.6 → 74.7) and SimpleQA (40.2 → 50.2) through targeted domain-specific training, resulting in superior AI capabilities.
Deployment Flexibility
Quantization Strategy
- Blackwell: Native NVFP4 execution for optimized performance
- Hopper: W4A16 emulation for enhanced efficiency
- Operating Point: 5.03 bits-per-element hybrid precision for superior accuracy
Open Access
Available under the OpenMDW-1.1 license with:
- BF16/NVFP4 checkpoints for seamless integration
- 50M SFT samples for extensive training
- 55 RL environments for diverse application testing
Real-World Applications
Agent-Centric Workloads
Proven effectiveness in:
- Software engineering (71.9 SWE-Bench Verified for high-quality results)
- Terminal operations (56.4 Terminal Bench 2.1 for operational efficiency)
- Mathematical reasoning (570.0 IOI 2025 for advanced problem-solving)
Industry Impact
Key sectors poised to benefit:
"Nemotron 3 Ultra's combination of throughput and context management makes it particularly valuable for enterprise automation and scientific workflows where long-running agents must maintain coherence across thousands of reasoning steps." – AI Infrastructure Analyst
Implementation Roadmap
Available Platforms
- NVIDIA NIM: Hosted API and deployable microservice for scalable solutions
- Hugging Face: Model weights and training recipes for easy access
- Together AI: Serverless inference solution for flexibility
- GitHub NeMo: Self-hosting guides and cookbooks for community support
Technical Resources
Comprehensive documentation includes:
- Comprehensive deployment playbooks for H100 and GB200 AI clusters
- In-depth LoRA fine-tuning tutorials for optimized AI performance
- Detailed agent-harness integration guides for seamless AI implementation
Future Outlook
NVIDIA positions Nemotron 3 Ultra as a foundation for next-generation AI agents. Ongoing development will focus on:
- Enhanced multi-modal capabilities for improved AI interactions
- Real-time collaboration features for efficient AI teamwork
- Energy-efficient inference optimizations for sustainable AI solutions
As agent-based workflows become mainstream, this architecture sets new standards for balancing performance, cost, and scalability in enterprise AI deployments.